
Hands-Free Meetings
With hands-free meetings, the conversation does not get interrupted by having to push a button or asking for permission to speak.
By the innovative audio processing techniques described below, Televic is the first to completely remove the need for any manual action from the participants during the meeting.
- Optimized intelligibility for both in-room and remote participants
- Consistent audio coverage in any room configuration
- Reduced acoustic feedback for standalone and integrated systems
- Automatic speech recognition
Dynamic Mix Minus
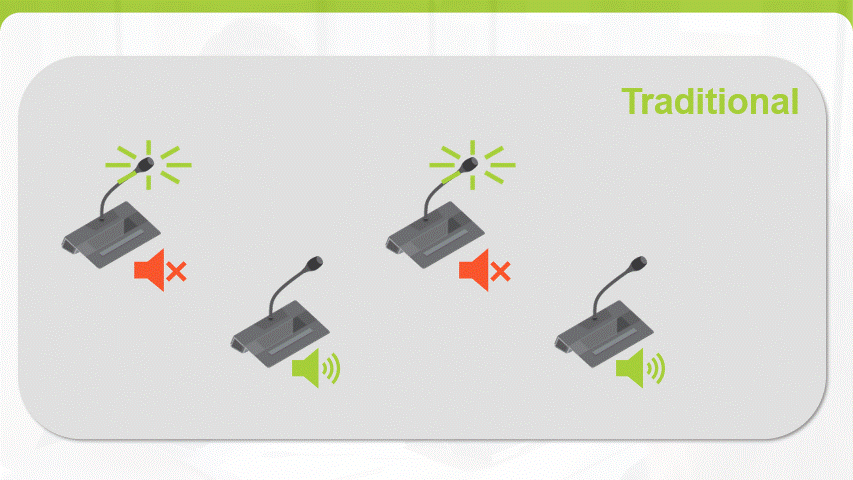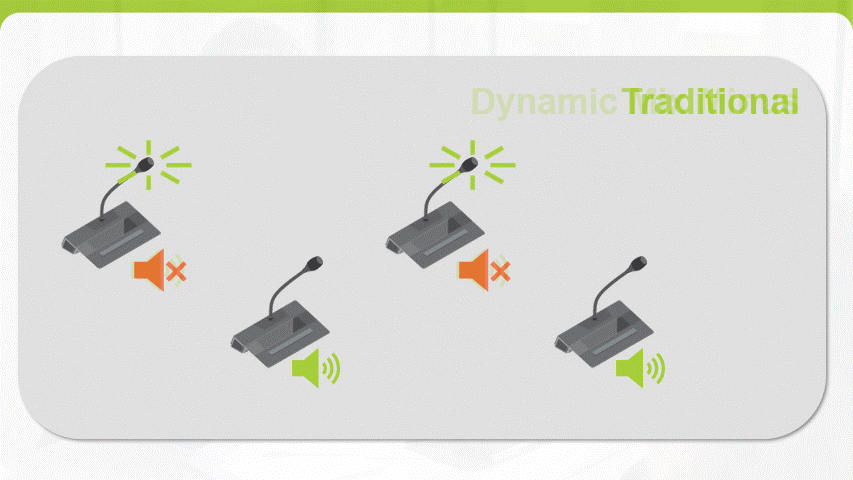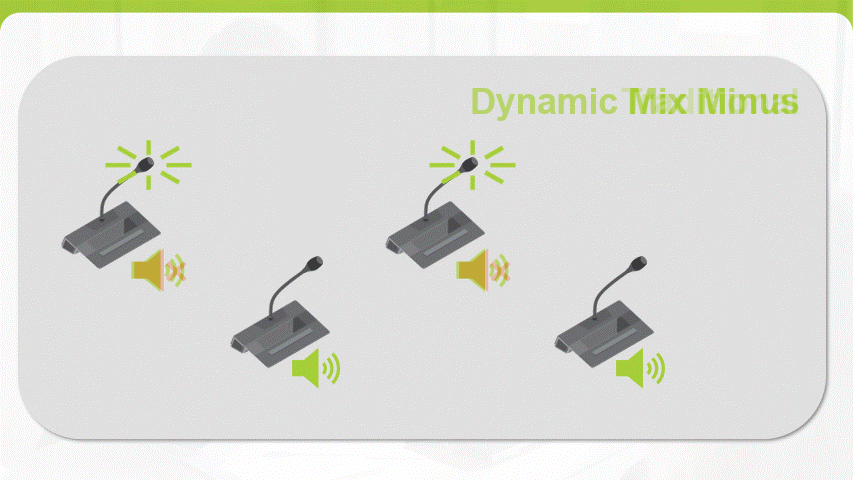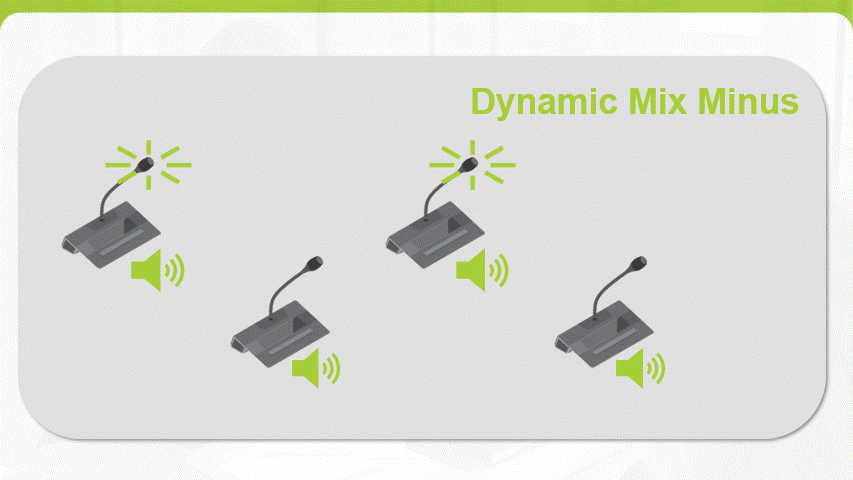
A common challenge during a meeting is hearing everyone and being heard, especially when some participants are joining remotely. Traditionally, the build-in loudspeaker of a conferencing unit is muted when the microphone is activated to reduce the chance of feedback but this results into a lowered intelligibility across the room. Televic has now introduced Dynamic Mix-minus which selectively removes the individual microphone audio channel from the mix each unit receives, drastically reducing the potential for echo or feedback. This new feature brings a consistent audio coverage for both in-room as remote participants independent of the size of the room.

Gain Sharing
Depending on the type of meeting, participants need to either push a button or request to speak before taking part in the conversation. The gain sharing algorithm within the hands-free microphone mode allows delegates to just start talking by allowing all microphones to be active at all times. This is achieved by sharing the gain between all microphones so that the participants that are speaking are getting their share of the gain while all other microphones are reduced. By automatically adjusting the gain of each microphone in real-time, this gain sharing algorithm ensures consistent audio levels, greater gain before feedback and a more natural listening experience for all participants.

Speech Detection
Although gain sharing allows for all microphones to be active all the time, it is still important to know who is speaking and when. By using a dedicated energy-based speech detection system, each active participant is automatically detected. This does not only allow the correct LED on the discussion unit to turn on but also triggers camera tracking to point to the correct delegate or feeds into the API for external integration.